大模型实战 P8 OpenAI接口实现Text Embeddings
关于文本嵌入 (Text Embeddings) 的过程,大家应该很熟悉了,在很早之前的 NER 项目里面,就给大家介绍过这个概念。但略有区别的是,之前是单个词的嵌入,这节课要介绍的是整个句子的嵌入,也就是转句向量。
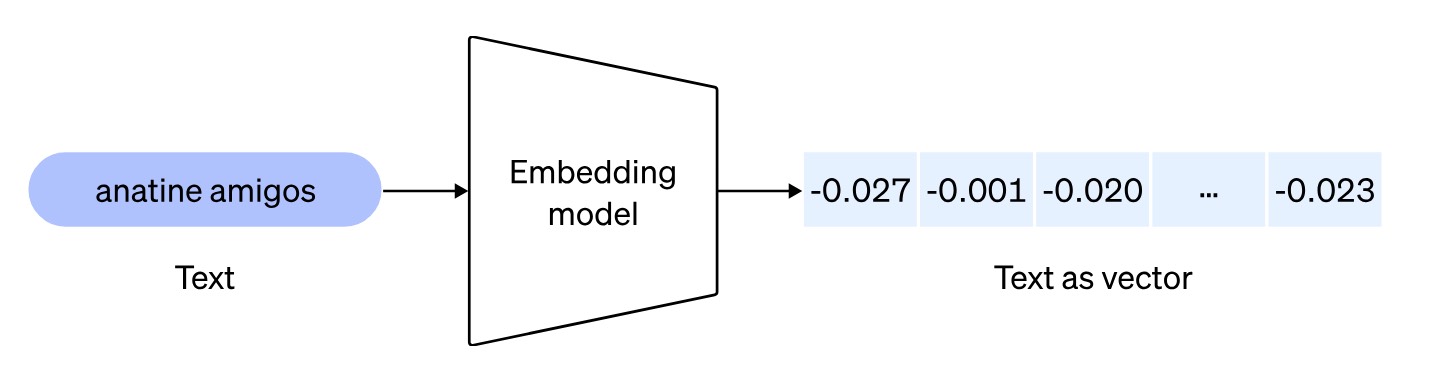
在当前这个项目中,文本嵌入的目的,就是做相关的文本检索,根据句向量的相似度,找到相关的文本。
相关文档
接口文档:https://platform.openai.com/docs/api-reference/embeddings
可选模型:https://openai.com/blog/new-and-improved-embedding-model
代码示例
1、单条数据
# openai_05_embeddings.py
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
response = client.embeddings.create(
model="text-embedding-ada-002",
input="感冒了吃什么药好得快?"
)
# print(response)
print(len(response.data[0].embedding))
2、多条数据
response = client.embeddings.create(
model="text-embedding-ada-002",
input=["感冒了吃什么药好得快?", "阿莫西林能治感冒吗?"]
)
for item in response.data:
print(len(item.embedding))
文本向量化的过程很简单,需要大家留意的是,转化之后向量的维度,不同的模型输出的维度是不同的,一般在一个项目中,只会使用一种模型进行编码,才能保证维度的一致性,否则维度不一致可能会报错。
本文链接:http://ichenhua.cn/edu/note/687
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



