Pytorch BERT_CasRel_RE P1-1 实体关系抽取项目介绍(1)
从本节开始,将带大家完成一个新的项目,叫做实体关系抽取。关系抽取(Relation Extraction)就是从一段文本中抽取出(主体,关系,客体)这样的三元组,用英文表示就是 (subject, relation, object) 这样的三元组。所以关系抽取,有的论文也叫作三元组抽取。
关系抽取,是信息检索、智能问答、对话机器人等人工智能应用的重要基础,一直受到业界的广泛关注。目前 NLP 领域的主流研究中,基于关系的知识图谱方向也是一个重要的分支。因为人们发现多音字、多义词,加上语境变化,单个字或者词的表征一定是片面的,发现实体之间的联系,往往比自身特征更重要。
关系识别的三种场景
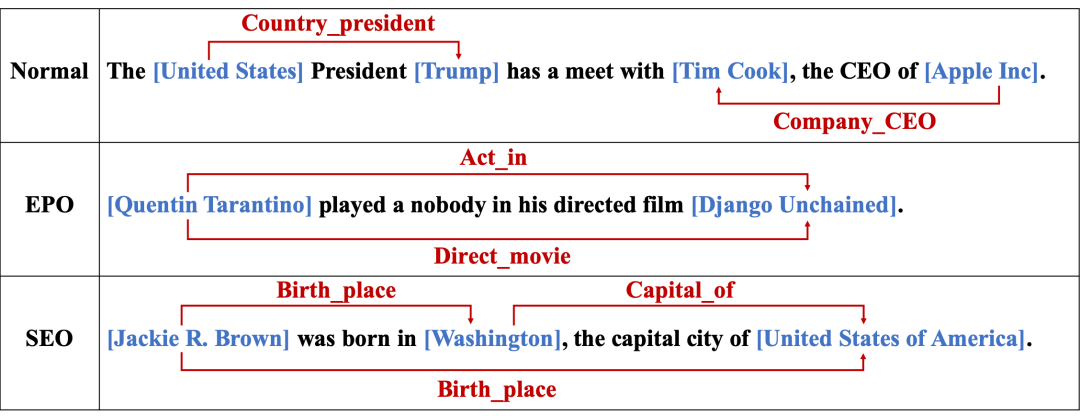
Normal表示三元组之间无重叠;EPO表示两个实体有两个完全不同的关系的情形,SEO表示一个实体参与到了多个关系中的情形。
效果演示
1)我只训练了5个 EPOCH,f1-score:0.632,模型效果一般;
2)对于参数量巨大的 BERT 模型来说,这个量是远远不够的,而且还有很多超参,课程中会介绍调参方法;
3)本项目在 CPU 上很难出效果,课程最后会介绍使用 Kaggle GPU 进行模型训练的方法。
text = '周杰伦将于7月15日发布2022新专辑《最伟大的作品》。'
[('最伟大的作品', '歌手', '周杰伦')]
text = '俞敏洪,出生于1962年9月4日的江苏省江阴市,大学毕业于北京大学西语系。'
[('俞敏洪', '毕业院校', '北京大学')]
模型结构预览
模型名称:CasRel,层叠式指针标注
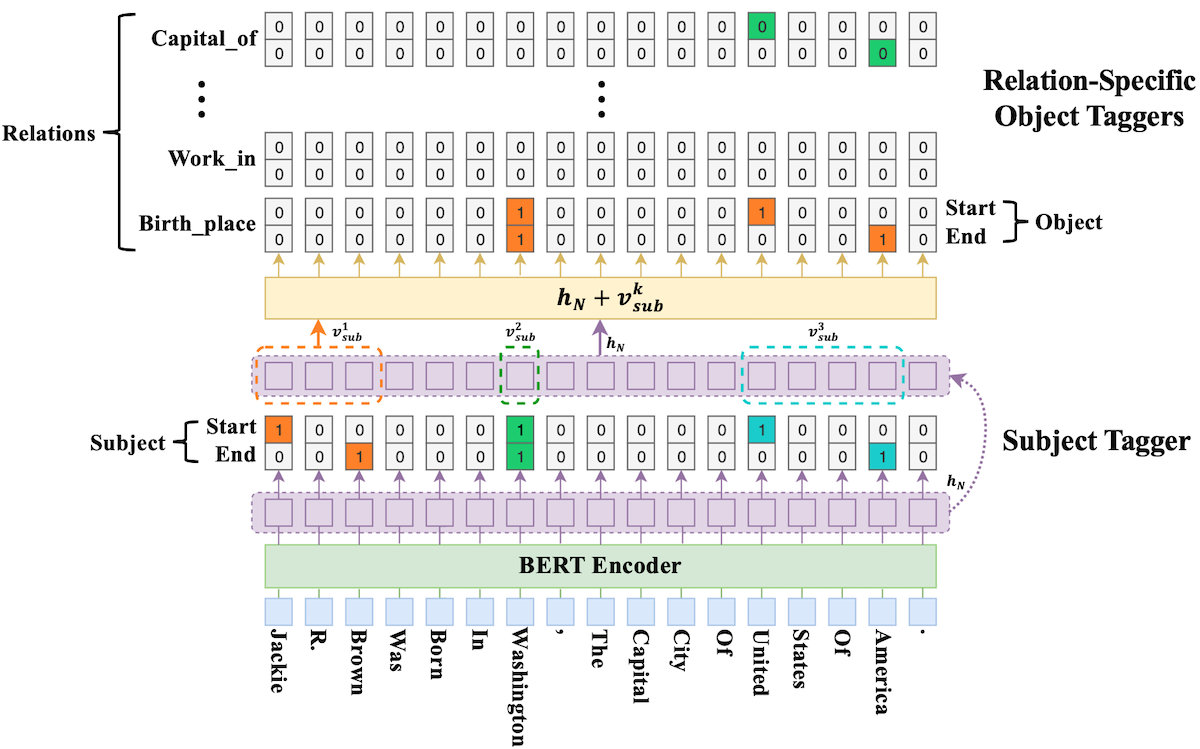
补充说明
1)总体来说,信息提取任务(关系、事件等)在 NLP方向,是一个比较难的任务,目前也还没有通用方案,还有很大的探索空间;
2)这个项目的代码量相对比较大,逻辑相对复杂,如果是 NLP算法 初学者,建议往后放一放;同时,讲解这个项目的难度也很大,希望大家可以多多点赞支持。
本文链接:http://ichenhua.cn/edu/note/477
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



