NER项目 P11-1 Bug修复和Kaggle GPU模型训练(1)
前面的课程中,前面我们花了10节课的时间,已经给大家把这个项目讲完了。但最近有同学反馈了一些问题,我挑了几个频率比较高的问题,给大家集中讲解一下。
三个方面的问题
1、代码报错,原因是CRF这个三方库更新了,需要微调代码;
2、训练时间太长,给大家介绍一个使用 Kaggle GPU 训练模型的方法;
3、测试准确率虚高,效果并不好,借助 seqeval 的一个评估函数,来查看少数类的准确率。
代码示例
1、CRF三方库更新
a)self.crf = CRF(TARGET_SIZE, batch_first=True)
b)viterbi_decode报错的问题:改成 return self.crf.decode(out, mask)
c)误差值太大的问题:return -self.crf.forward(y_pred, target, mask, reduction='mean')
2、Kaggle GPU加速训练
a)注册、登录,网址:https://www.kaggle.com/
b)上传 Dataset 到 Kaggle
c)复制代码到 Notebook,并修改代码。原则是,要保证数据和模型在同一个设备上
内容不可见,请联系管理员开通权限。
d)切换GPU,在线和离线训练
3、模型文件下载
a)注意,要将 vocab.txt 和 label.txt 文件一并下载下来,不同环境生成的文件不一样;
b)不一样的原因,是数据预处理阶段,随机拆分了训练集和测试集,随机产生的训练集不同,生成的词表文件也会不同。
4、多分类评估指标
sklearn 的评估指标统计的是单个标签,seqeval 统计的是实体,更严格。
内容不可见,请联系管理员开通权限。
测试效果
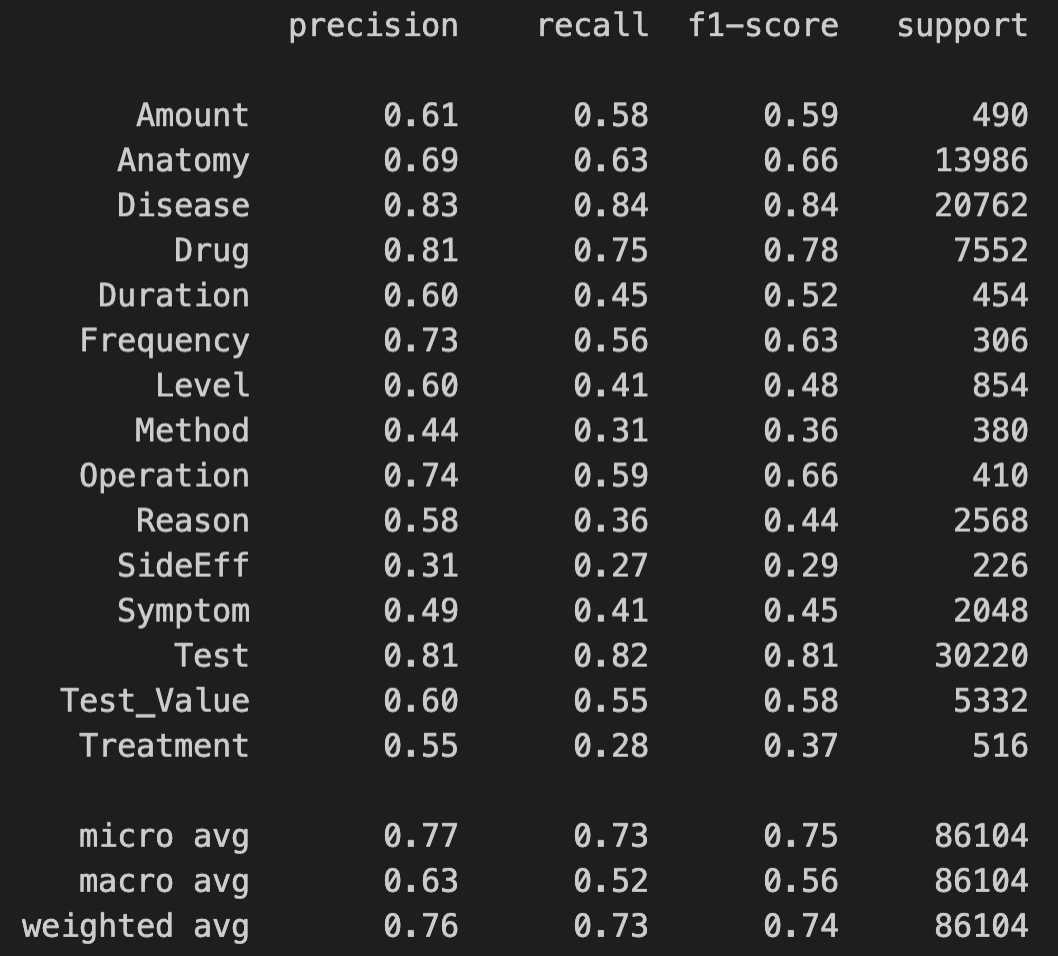
目前这个效果,差不多已经到极限了,当时大赛的最好成绩也只有0.763,因为选手用特征工程手段,对样本数据进行了修正,效果会稍好一些。那我们这个项目,也就先到这里,后面我们学完 Bert 之后,大家可以回来,把模型中的随机 Embedding 层,换成 Bert,可能会有更好的效果。
本文链接:http://ichenhua.cn/edu/note/463
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



