CasRel项目 P2 模型结构详解与局限性分析
上节课,给大家整体介绍了项目要做的事情,就是从一段文本当中,找到主体、客体、和关系的三元组组合,因为 CasRel 这个模型,设计思路不是很常规,示意图的细节也容易混淆,所以我们单独用一节课时间,来拆解一下这个模型。
任务分解
关系抽取(Relation Extraction)就是从一段文本中抽取出(主体,关系,客体)这样的三元组,用英文表示就是(subject, relation, object)这样的三元组。
从关系抽取的定义也可以看出,关系抽取主要要做两件事:
1)识别文本中的subject和object(实体识别)
2)判断这两个实体属于哪种关系(关系分类)
Pipeline 和 Joint Model
在解决关系抽取这个任务时,按照模型的结构分为两种,一种是 Pipeline,另一种是 Joint Model。
如果将关系抽取的两个任务分离,先进行实体识别,再进行关系分类,就是 Pipeline 模型。但这样存在的问题是,会出现误差传播的情况,也就是实体识别的误差,会影响后面的关系分类任务,但关系分类任务,又无法对实体识别造成的误差进行修正。因为两个任务是独立的,关系分类的loss,无法反向传播给实体识别阶段。
为了优化 Pipeline 存在的问题,就有了 Joint Model(多任务学习的联合抽取模型),实体和关系共享同一个encoder网络编码,解码仍然是两个decoder,本质上还是 Pipeline 的编码方式,也就是先解码出实体,再去解码关系。但跟 Pipeline 不同的是,Joint Model 只计算一次损失,所以loss反向传播,也会对实体识别的误差进行修正。
模型结构详解
我们这个项目用的是 CasRel模型,是众多关系抽取模型中的一种,发表于2019年,虽然近年来不断有新的模型提出,但业界还没有统一方案。选用这个模型的原因,是它有一定的代表性和知名度,而且能帮助大家增进编码能力。
论文标题:A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
模型简称:CasRel,层叠式指针标注
论文链接:https://arxiv.org/abs/1909.03227
论文代码:https://github.com/weizhepei/CasRel(TensorFlow、英文数据集)
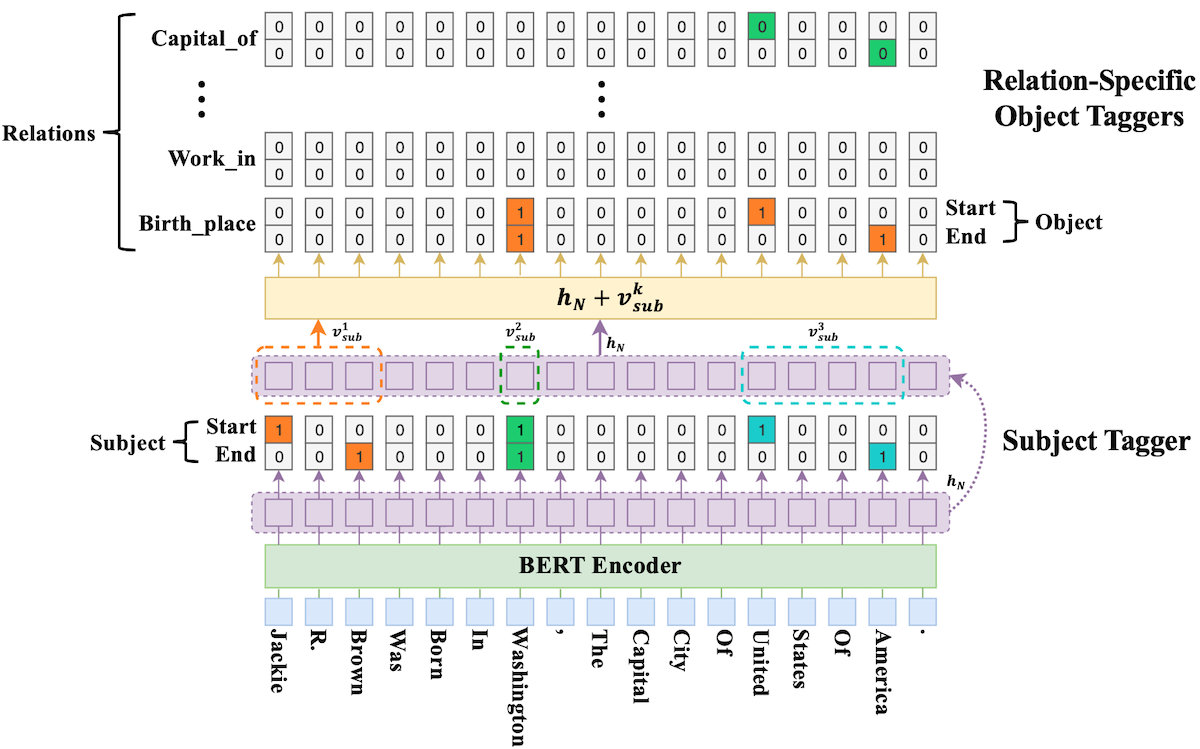
模型局限性
1)因为实体就近匹配,无法解决实体嵌套的场景,例如:叶圣陶散文选集、叶圣陶;
2)该模型不适用于长段落、篇章级别信息抽取,因为bert位置编码512位,关系无法跨句子;
3)目前知识图谱运用场景还是聚焦在垂直领域,因为开放式关系抽取很困难,关系数量 r = n(n-1)/2。
这个任务既充满挑战,又有很大的探索空间,值得学习。
本文链接:http://www.ichenhua.cn/edu/note/478
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



